
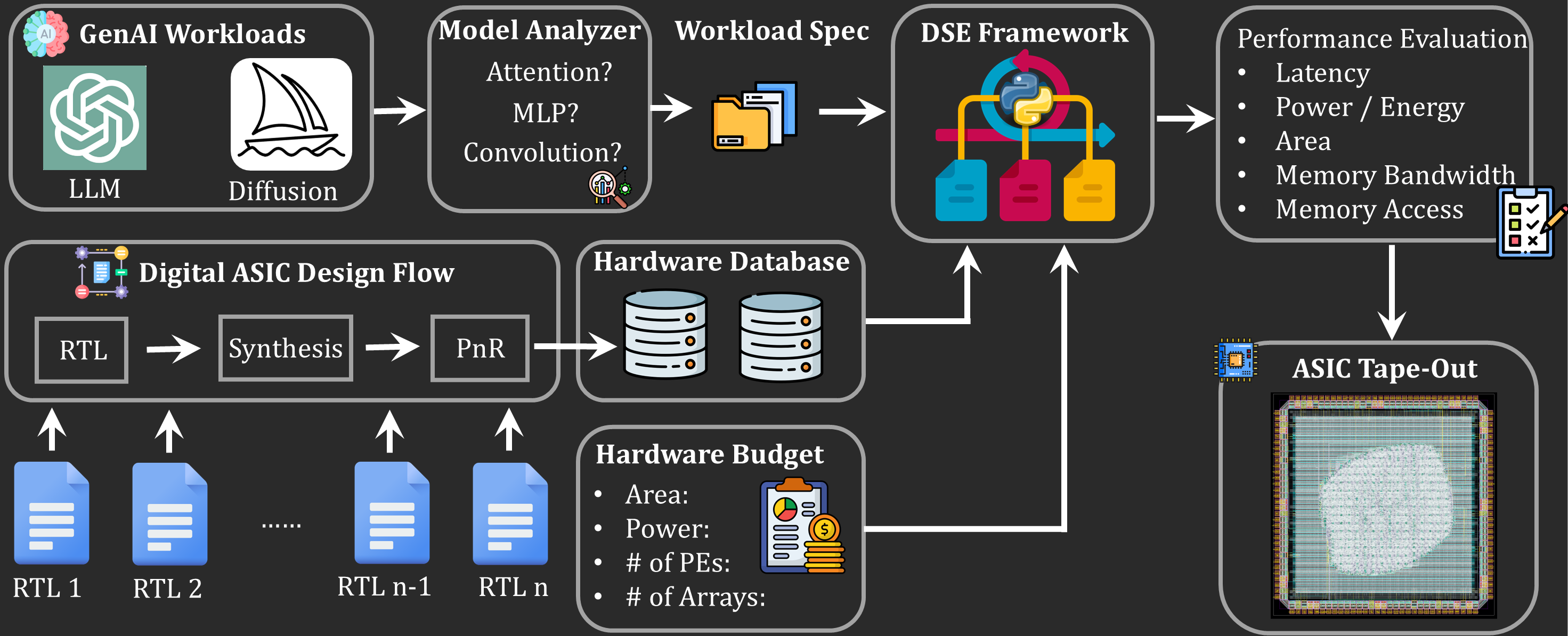
When I start exploring a new AI accelerator idea, I usually try to avoid jumping directly into RTL. The first few days are much more productive when the workflow is structured around fast feedback: define the problem, set a few measurable targets, and build a lightweight model that makes trade-offs visible.
This is especially important for systolic and dataflow-driven architectures, where small choices in tiling, buffering, or operand movement can dominate the final performance and energy story.
1. Start with the bottleneck, not the block diagram
It is tempting to begin with a clean architecture drawing. In practice, I get better results by starting from one question:
What is the real bottleneck for this workload under a realistic resource budget?
For example, in a transformer-oriented accelerator study, the answer is often not simply “MAC throughput.” It may be:
- on-chip SRAM capacity
- activation movement between tiles
- reduction latency
- utilization collapse on irregular shapes
Once that bottleneck is clear, the architectural discussion becomes much sharper.
2. Build a small model before building detailed hardware
My preferred first step is a compact simulator or analytical model that can answer:
- cycle estimate
- buffer requirement
- PE utilization
- data reuse opportunity
- communication pressure
It does not need to be perfect. It only needs to be fast enough to compare design choices honestly.
For instance, a simple configuration table like this is already useful:
workload:
m: 4096
n: 4096
k: 4096
array:
rows: 16
cols: 16
mapping:
tile_m: 128
tile_n: 128
tile_k: 64
dataflow: output-stationary
With a setup like this, I can quickly test whether a change in tile size improves reuse or only increases control complexity.
3. Keep the evaluation metrics simple and comparable
At the beginning, I try to track only a few metrics consistently:
- total cycles
- estimated memory traffic
- utilization
- latency to first output
- basic area proxies such as buffer count or array size
Even rough metrics are valuable if they are measured in a consistent way across all candidates.
4. Delay implementation detail until the design space becomes narrower
I have learned that early over-implementation can hide weak ideas behind a lot of code. If the model still shows unclear trade-offs, it is usually too early to optimize controllers, interfaces, or verification infrastructure.
Once two or three promising candidates remain, then it makes sense to move toward:
- a cleaner simulator
- RTL microarchitecture sketches
- interface definition
- verification planning
That transition is much easier when the earlier exploration already established why a design should exist.
Closing thought
Good accelerator work is not only about building fast hardware. It is also about building a workflow that helps us reject bad assumptions early.
That is the kind of note I want to keep sharing here: small, practical ideas from architecture exploration, hardware implementation, and research-in-progress.